
NVIDIA’s video analytics AI agents are something to call upon for the next evolution in smart video systems, moving beyond the limitations of traditional object detection models. For years, video analytics systems have been relying on fixed-function algorithms trained to recognize a predefined set of objects and events. Although they are indeed effective for basic monitoring, their lack of contextual awareness and narrower operation boundaries have created a need for more adaptive and intelligent solutions.
The emergence of generative AI and multimodal foundation models is making what was once impossible. The combination of computer vision with natural language processing powers up these video analytics AI agents to interpret complex scenes, respond to human queries, and provide meaningful insights from video data.
Through this guide to understanding the video analytics AI agents, we will explain their capabilities, features, architecture, and real-world use cases across industries. Let’s get started!
What are Video Analytics AI Agents?
Video analytics AI agents are a combination of vision-language models with large language models and retrieval systems to interpret video content in context. Instead of recognizing isolated objects, these agents generate descriptive representations of scenes, track temporal patterns, and maintain indexed memory across long video timelines. Natural language queries can then be mapped to this structured understanding of video data.
In enterprise implementations from NVIDIA, orchestration layers such as NVIDIA NIM manage model inference, routing, and scaling. Vision-language models analyze frames and produce dense captions. Language models interpret intent within user queries. Retrieval pipelines connect questions to relevant video segments while preserving contextual continuity across time.
This architecture enables systems to answer operational questions rather than merely flag predefined events. An agent can correlate object behavior across minutes or hours, distinguish between normal and abnormal patterns, and support investigative workflows across multiple streams.
In production environments, this reduces manual video review, improves incident response accuracy, and transforms surveillance infrastructure into an analytical decision-support layer rather than a passive recording system.
How Does a Video Analytics AI Agent Work?
A video analytics AI agent works by breaking video into structured, searchable knowledge and then applying reasoning over that knowledge. The process starts with ingestion. The system receives a live stream or recorded file and divides it into smaller chunks.
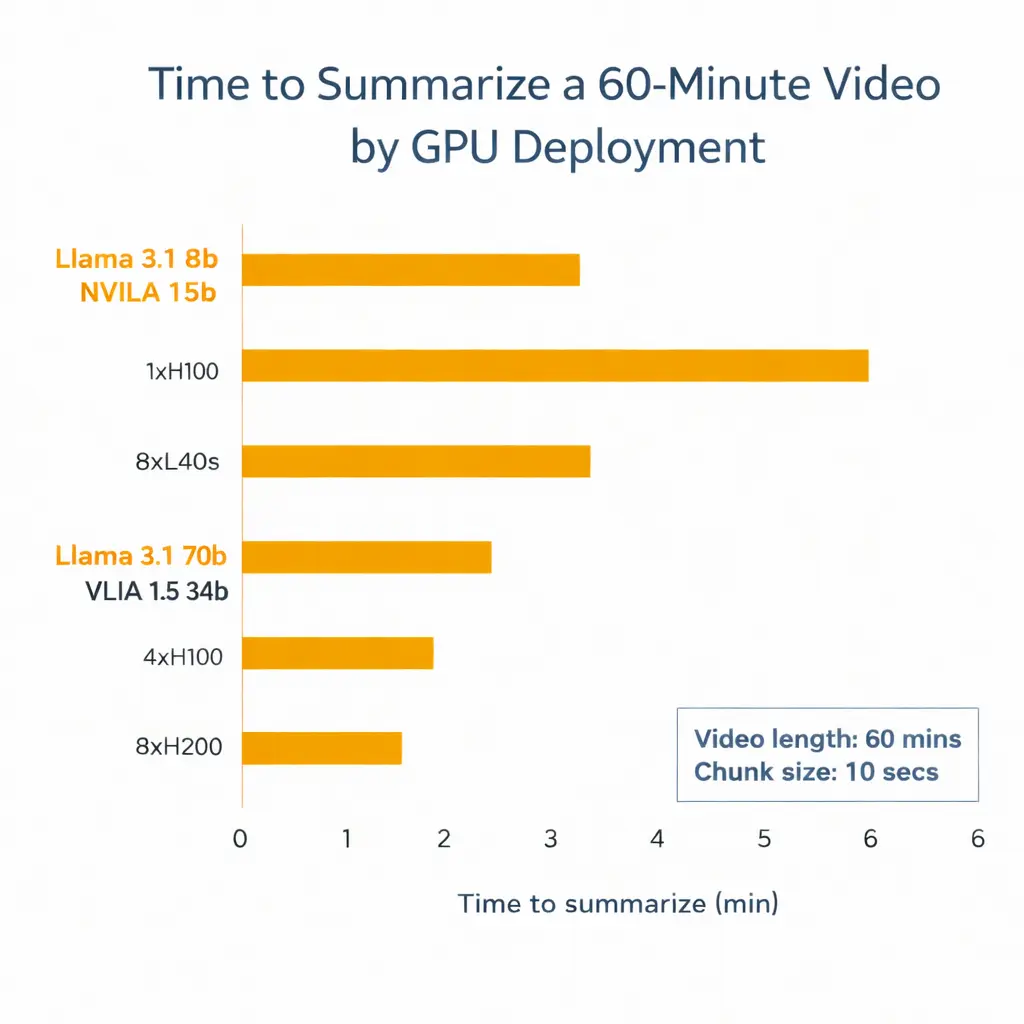
Short segments capture fast events but increase processing load. Longer segments reduce model calls but may blur temporal detail. In production deployments, teams often adjust this based on camera density, GPU availability, and required response time.
Each chunk moves through a vision-language model. This model examines sampled frames and generates dense captions that describe objects, actions, and scene context in plain language.
Instead of outputting bounding boxes alone, it produces narrative descriptions tied to timestamps. Some deployments extend this step with object tracking metadata from computer vision pipelines so the agent can distinguish between similar objects across time.
The system then stores these captions as embeddings inside a vector database. If graph-based retrieval is enabled, it also extracts entities and relationships into a graph structure. When a query arrives, a language model interprets intent, retrieves relevant chunks through similarity search, and assembles context before generating a response.
Core Capabilities of Video Analytics AI Agents
Here are some core capabilities of NVIDIA's video analytics AI agents:
Context-Aware Scene Understanding
A video analytics AI agent starts its reasoning process with a Vision-Language Model (VLM). The VLM examines sampled video frames and generates dense captions that describe objects, actions, and environmental context in structured language. Unlike traditional detectors that output bounding boxes alone, the VLM translates visual data into searchable descriptions tied to timestamps.
When deployments enable object tracking metadata, SoM prompting (Set-of-Mark prompting) strengthens visual grounding. Object IDs, segmentation masks, and bounding boxes guide the VLM so responses reference specific tracked entities rather than generic scene summaries.
Natural Language Query Handling
Once captions are generated, the system embeds them into a retrieval layer.
- The VLM converts video into descriptive text.
- The LLM interprets investigative queries.
- The RAG pipeline retrieves relevant indexed segments before response generation.
This architecture prevents hallucinated answers because the language model grounds responses in retrieved evidence. In large-scale deployments, this separation between generation and retrieval improves reliability during compliance audits and operational reviews.
Implementations from NVIDIA coordinate this orchestration through services such as NVIDIA NIM, which manage inference workloads across GPUs.
Multimodal Fusion with Audio Intelligence
Video alone does not capture the full operational context. The blueprint integrates audio transcription through NVIDIA Riva. Audio streams are separated, converted to a standardized format, and processed through NVIDIA Riva ASR to generate transcripts aligned with video timestamps.
The system then merges visual captions, CV metadata, and audio transcripts into unified embeddings stored in vector and graph databases. This allows the agent to correlate spoken instructions with observed actions, improving investigative depth and anomaly detection.
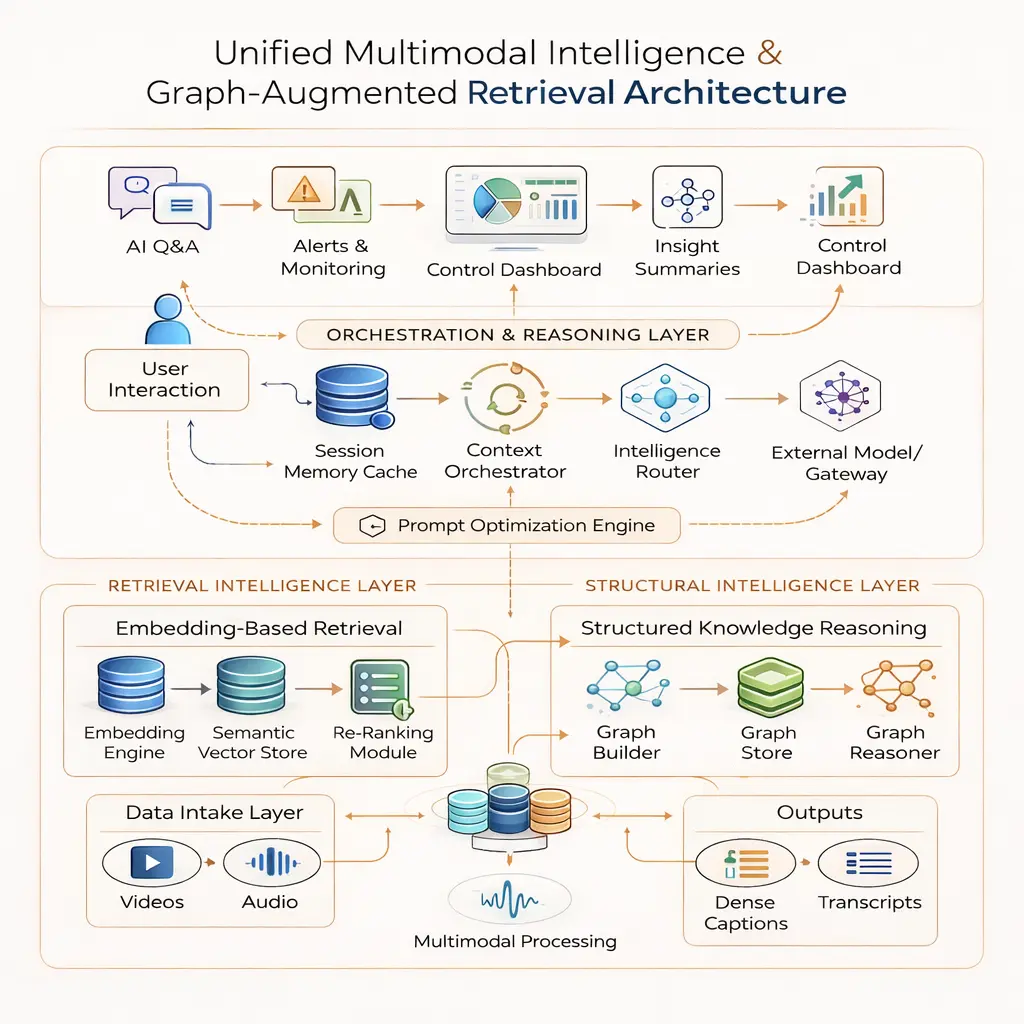
Architecture of a Video Analytics AI Agent
An NVIDIA video analytics AI agent follows a modular architecture designed for long-form video understanding, multi-stream processing, and real-time reasoning. The system does not operate as a single monolithic model. Instead, it separates ingestion, visual interpretation, retrieval, reasoning, and multimodal processing into distinct layers.
Ingestion and Stream Management Layer
An NVIDIA video analytics AI agent begins at the ingestion layer. Live streams or recorded files enter the system and pass through a chunking process. Each chunk receives a stream identifier. This prevents context leakage across feeds when multiple cameras are processed in parallel. In large facilities, improper stream isolation leads to cross-referenced summaries and unreliable answers. Stream tagging avoids that failure point.
Vision and Caption Generation Layer
The next layer runs a Vision-Language Model (VLM). The VLM analyzes frames and generates dense captions tied to timestamps. When the deployment enables object tracking metadata, SoM prompting strengthens grounding. Object IDs and segmentation masks guide the model so it refers to specific tracked entities rather than generic descriptions.
This stage converts visual data into structured language. That conversion forms the foundation for downstream reasoning. Without reliable caption quality, retrieval accuracy degrades quickly.
Retrieval and Reasoning Layer
Once generated, captions move into embedding services and indexing. The architecture relies on VLM + LLM + RAG pipelines for Q&A and summarization. The VLM describes. The LLM interprets queries. The RAG layer retrieves relevant segments before response generation.
In implementations from NVIDIA, orchestration runs through NVIDIA NIM microservices. These services manage inference scheduling, GPU allocation, and scaling controls. In multi-stream deployments, improper batching often creates latency spikes. NIM’s isolation of model services helps reduce that bottleneck.
Multimodal and Audio Integration
When enabled, audio flows through NVIDIA Riva for transcription. The system aligns transcripts with visual captions before indexing.
This fusion strengthens contextual reasoning. It allows the agent to correlate spoken instructions with observed activity and improves investigative depth in environments where audio carries operational significance.
Industry-wise Use Cases of Nvidia Video Analytics AI Agents:
An NVIDIA video analytics AI agent becomes valuable when it operates inside real operational environments rather than controlled demos. The following use cases reflect how these agents function under practical enterprise conditions.
Smart Cities and Traffic Infrastructure
Urban deployments generate continuous multi-camera streams across intersections, highways, and transit hubs. Traditional systems detect congestion or red-light violations based on fixed rules. A video analytics AI agent processes streams using Vision-Language Models (VLMs) to generate dense captions and track vehicles through SoM prompting.

City operations teams can query historical footage using natural language. The VLM + LLM + RAG pipelines for Q&A and summarization retrieve relevant segments tied to specific time ranges or vehicle behaviors. When integrated with traffic control systems, alerts trigger based on contextual understanding rather than isolated object detection.
GPU scheduling and stream isolation, often orchestrated through services from NVIDIA and NVIDIA NIM, determine whether analysis remains real-time during peak traffic hours.
Warehousing and Industrial Facilities
Warehouses operate under strict safety and productivity targets. Camera systems monitor loading docks, forklift movement, and restricted areas. An NVIDIA video analytics AI agent tracks object IDs over time and correlates behavior across camera zones.
Operations managers can review events such as prolonged idle time, unsafe crossings, or loading delays without manually scanning hours of footage. Temporal reasoning within the retrieval layer supports this investigation.

Industrial networks often run on constrained edge infrastructure. Many deployments rely on Jetson-based hardware to perform inference locally, reducing bandwidth dependency. This edge processing prevents overload of central servers and maintains analysis during network interruptions.
Retail and Physical Stores
Retail environments require behavioral analysis rather than simple footfall counting. A video analytics AI agent interprets shopper movement patterns, queue formation, and dwell time near high-value products.
Audio processing through NVIDIA Riva strengthens context in stores that record customer service interactions. When transcripts align with visual metadata, the system can correlate complaints with observed service delays.

Data retention policies in retail environments demand strict access control. Retrieval pipelines must isolate store-level streams and prevent cross-location data leakage.
Airports and Transportation Hubs
Airports manage high-density movement across terminals, security checkpoints, and boarding gates. An NVIDIA video analytics AI agent assists in anomaly detection, unattended baggage identification, and crowd pattern monitoring.
Multi-stream coordination becomes essential. The system must maintain context per terminal while enabling cross-zone investigation during incidents. Improper batching or indexing strategies increase response time and degrade reliability during high passenger volume.
In regulated environments such as aviation, audit trails matter. Retrieval-backed responses grounded in indexed captions provide traceable evidence rather than model-generated assumptions.
Conclusion
Video analytics AI agents redefine how enterprises extract value from surveillance infrastructure. Instead of relying on predefined object detection rules, these systems build structured, timestamped knowledge from video streams and apply reasoning over that data.
By combining Vision-Language Models, Large Language Models, retrieval pipelines, and audio transcription within NVIDIA’s modular architecture, they deliver contextual understanding across long timelines and multiple camera feeds.
Across smart cities, retail, industrial facilities, and transportation hubs, these agents function as analytical decision-support systems by improving response accuracy, strengthening compliance readiness, and enabling scalable, production-grade intelligence across complex environments.
FAQs
What is the Nvidia AI Blueprint for Video Analysis?
The NVIDIA AI Blueprint for Video Analysis is a modular reference architecture combining Vision-Language Models, LLMs, RAG pipelines, and NVIDIA Riva to enable contextual video understanding, retrieval-based Q&A, and scalable multi-stream processing.
Can an AI Analyse a Video?
Yes, AI can analyze video by processing frames through Vision-Language Models, generating timestamped captions, indexing embeddings, and applying retrieval and reasoning layers to answer queries or detect patterns across time.
What is AI-enabled Video Analytics?
AI-enabled video analytics uses multimodal AI models to convert video and audio into structured, searchable knowledge. It supports contextual scene understanding, natural language queries, anomaly detection, and evidence-backed decision-making in enterprise environments.
